

3·
21 hours agoAh, you’re right - I misunderstood jbrain’s point to just be about the “relative to the original” understanding. Guess I’m no smarter than Google’s AI.
New account since lemmyrs.org went down, other @Deebsters are available.
Ah, you’re right - I misunderstood jbrain’s point to just be about the “relative to the original” understanding. Guess I’m no smarter than Google’s AI.
Yes, and the Google AI response is correct (and quite clear) in what it says. edit: Thanks Batman. I mean that Google’s understanding of the question is logical (although still the maths is wrong as you say (now I’ve re-read you)) and its answer explained the angle it was answering from.
However, I think the reasonable assumption for the intention behind the question is relative to a whole. I had third of a pizza, and now I have an extra sixth of a pizza. It’s subtle, but that’s the kind of thing AI falls down on.
Google’s AI seems dumber than the rest, for example here’s Kagi answering the same (using Claude):
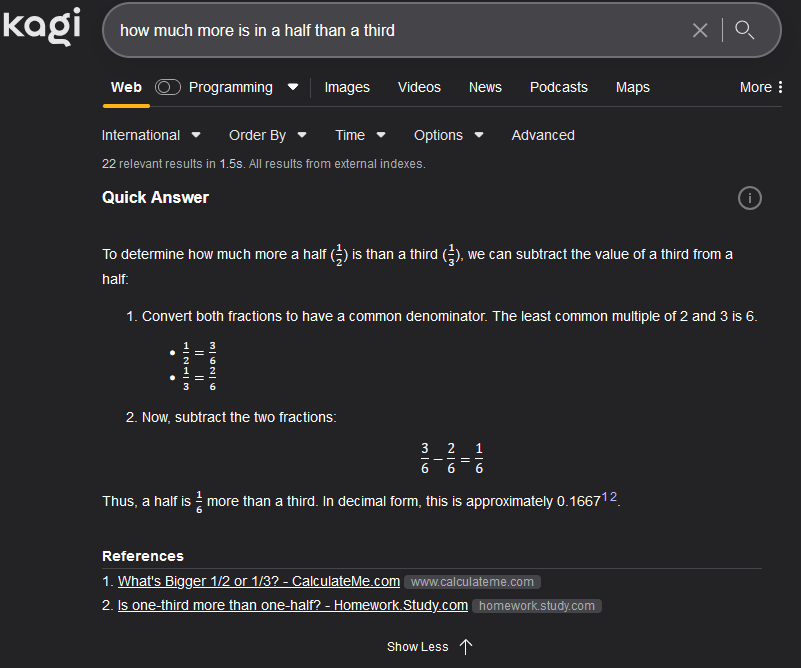
edit: typoed question originally
Perhaps Google’s tried to make it run too cheaply - Kagi’s one doesn’t run unless you ask for it, and as a paid product it’ll have different priorities.

While I don’t disagree, this article is pretty bad and unconvincing. Is it a draft or something dashed out to collect referral fees?
It shows the top line, so you just read top to bottom (and can scroll if you want).
You can set it to show what you want; if I’m doing TDD I’ll set it to show the test output, and then it’ll show the warnings beneath it.
You can switch between the views with a key (T for tests (or N for nextest), C for clippy, etc
But yes, it’s pretty similar to using watch.
My hope is that something like Servo gets good enough to be included, especially if it’s tree-shakable so you can only include a subset of the codebase. I don’t know if that’s a goal for either projects, but it would be cool - the default webviews can be quite lacking so currently you need to use a restricted set of HTML/CSS/JS to guarantee compatibility.

Because this is the internet, I can’t tell if the whoosh goes to your downvoters or you. I think you were joking, but that second sentence makes me wonder…
I pay for Nebula - $30 a year which is about £22.50. That won’t even cover two months of YouTube Premium (£12 pm), and there’s not even the discounted yearly option in the UK.
And “if you’re not paying you’re the product” is wrong - YouTube/Google would still be datamining my viewing habits to sell to advertisers.
Perhapsburg they are
Only if enough people do it. Then again, loads scrapers outside of AI already pretend to be normal browsers.
The term you want is “cross compile”. I’ve developed simple programs for the Pi on Windows and it’s simple enough to produce a static binary (using Rust, anyway). When extra dependencies come in it’s better to develop on the same OS, but targeting different architectures is the easy bit.

How did you find Leptos to work with? I never got further than the tutorial so I have yet to form a real opinion on it.
It’s a subtle difference between that and path::exists().
path::exists() == false might just mean you can’t use it (if path::exists() cannot access a file due to e.g. permissions, it’ll return false)fs::exists() == Ok(false) means it’s definitely not there (permissions error will cause an Err to be returned)The source story is worth a read.
Marrero’s background is in Navy intelligence, and she earned a master’s degree in business administration with a concentration in information security and digital management
Incredible.
she soon changed the “STINKY” Wi-Fi network name to another moniker that looked like a wireless printer — even though no such general-use wireless printers were present on the ship
Why not just switch off broadcasting the SSID?
[The CO and XO] then conducted another sweep inside the ship. Although the network that appeared to be a wireless printer appeared on their personal devices during their search, neither made additional inquiries regarding that network
No-one’s coming out of this looking good.
Marrero’s secret Starlink dish was removed the same day, and Marrero told another unidentified crew member the next day that it was authorized for in-port use — prompting sailors to re-install the illegal Starlink.
It just keeps going!

There’s kroki as well, which includes Mermaid, Excalidraw, GraphViz, PlantUML, etc.
I’m of the belief that spawning threads on demand is an anti-pattern; threads should spawn on program startup, and sleep until they have work to do.
Hmm, I need to think on this to decide whether I agree. What’s your reasoning for this opinion? Is it just based on lower latency, or is it more of an architectural/correctness thing?
I thought it was clever, but now I’m seeing what I assume you’re seeing.
There’s moderation per community and per server. There’s no “fediverse moderator”, of course, but I think you’re vaguely worrying for nothing.
{kind=link}
{kind=link}
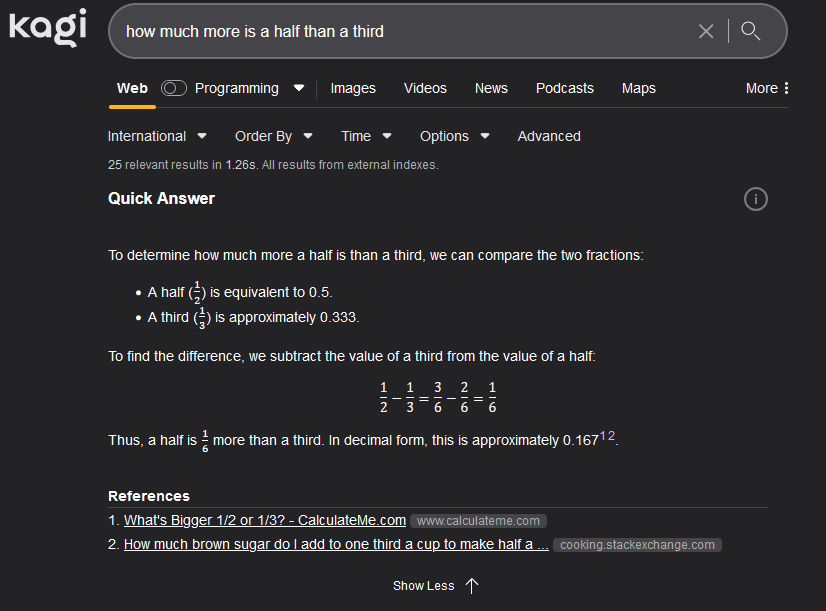
I thought we were finally agreeing fully! My understanding of the question is “what is the difference between a third (of a pizza, say) and a half?”
1/2 - 1/3 = 1/6
1/2 = 1/3 + 1/6
a half is one sixth more than a third.
btw, I fixed my Kagi screenshot since I’d missed a word from the question (reading comprehension’s clearly not my strong point today)