Atemu
Interested in Linux, FOSS, data storage systems, unfucking our society and a bit of gaming.
I help maintain Nixpkgs.
https://github.com/Atemu
https://reddit.com/u/Atemu12 (Probably won’t be active much anymore.)
- 10 Posts
- 187 Comments

It’s a central server (that you could actually self-host publicly if you wanted to) whose purpose it is to facilitate P2P connections between your devices.
If you were outside your home network and wanted to connect to your server from your laptop, both devices would be connected to the TS server independently. When attempting to send IP packets between the devices, the initiating device (i.e. your laptop) would establish a direct wireguard tunnel to the receiving device. This process is managed by the individual devices while the central TS service merely facilitates communication between the devices for the purpose of establishing this connection.
If you’re worried about that, I can recommend a service like Tailscale which does not require permanently open ports to the outside world, offering quite a bit more security than an exposed traditional VPN server.

 2·7 months ago
2·7 months agoHe had the last 6 months or so to work on it. He resigned from the Nouveau project and RH in September and likely joined Nvidia a little while later where he would have had plenty of time to work on this patch series.
 16·7 months ago
16·7 months agoOh I’m sure your health insurance would love to know the condition of your teeth to increase your rates.
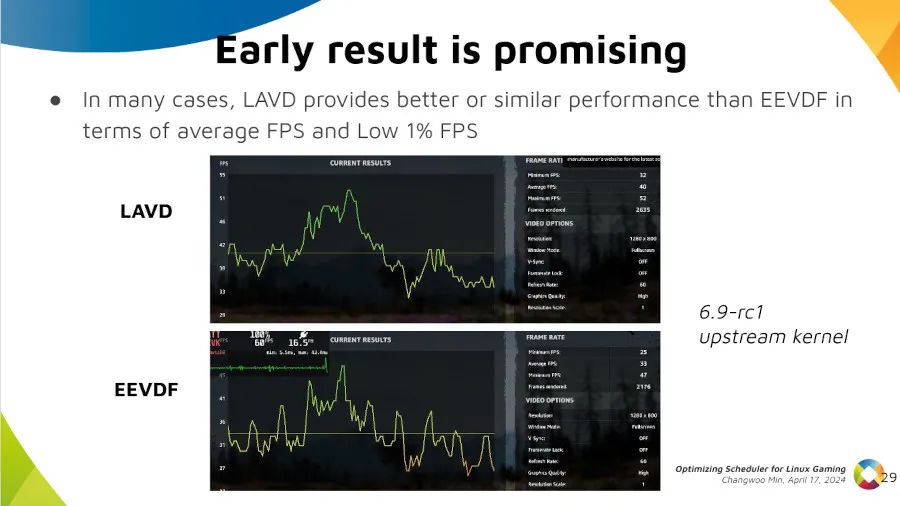
 5·7 months ago
5·7 months agoYes, yes they will. If you’re the sole user, they’d identify you from your behaviour anyways.
I don’t think internet proxy won’t help very much w.r.t. privacy but it will make you a lot more susceptible to being blocked.
Why not?

Plenty more benchmark worse. What’s your point exactly?
Statistically it should always be better by now because the resource hog that is called windows slows older systems down.
That’s not how any of this works.
voxe-lee-bruh
Does it work if you enable VRR via xorg config?
Which xorg driver are/were you using, amdgpu or modesetting?
I am not. Read the context mate.

They were mentioned because a file they are the code owner of was modified in the PR.
The modifications came from another branch which you accidentally(?) merged into yours. The problem is that those commits weren’t in master yet, so GH considers them to be part of the changeset of your branch. If they were in master already, GH would only consider the merge commit itself part of the change set and it does not contain any changes itself (unless you resolved a conflict).
If you had rebased atop of the other branch, you would have still had the commits of the other branch in your changeset; it’d be as if you tried to merge the other branch into master + your changes.
The thing is, you can get your cake and eat it too. Rebase your feature branches while in development and then merge them to the main branch when they’re done.
Note that I didn’t say that you should never squash commits. You should do that but with the intention of producing a clearer history, not as a general rule eliminating any possibly useful history.
you also lose the merge-commits, which convey no valuable information of their own.
In a feature branch workflow, I do not agree. The merge commit denotes the end of a feature branch. Without it, you lose all notion of what was and wasn’t part of the same feature branch.
The only difference between a *rebase-merge and a rebase is whether main is reset to it or not. If you kept the main branch label on D and added a feature branch label on G’, that would be what @andrew@lemmy.stuart.fun meant.
You should IMO always do this when putting your work on a shared branch
No. You should never squash as a rule unless your entire team can’t be bothered to use git correctly and in that case it’s a workaround for that problem, not a generally good policy.
Automatic squashes make it impossible to split commit into logical units of work. It reduces every feature branch into a single commit which is quite stupid.
If you ever needed to look at a list of feature branch changes with one feature branch per line for some reason, the correct tool to use is a first-parent log. In a proper git history, that will show you all the merge commits on the main branch; one per feature branch; as if you had squashed.Rebase “merges” are similarly stupid: You lose the entire notion of what happened together as a unit of work; what was part of the same feature branch and what wasn’t. Merge commits denote the end of a feature branch and together with the merge base you can always determine what was committed as part of which feature branch.
Because when debugging, you typically don’t care about the details of
wip,some more stuff,Merge remote-tracking branch 'origin/master',almost working,Merge remote-tracking branch 'origin/master',fix some testsetc. and would rather follow logical steps being taken in order with descriptive messages such ascomponent: refactor xyz in preparation for feature,component: add do_foo(),component: implement feature using do_foo()etc.
For merge you end up with this nonsense of mixed commits and merge commits like A->D->B->B’->E->F->C->C’ where the ones with the apostrophe are merge commits.
Your notation does not make sense. You’re representing a multi-dimensional thing in one dimension. Of course it’s a mess if you do that.
Your example is also missing a crucial fact required when reasoning about merges: The merge base.
Typically a branch is “branched off” from some commit M. D’s and A’s parent would be M (though there could be any amount of commits between A and M). Since A is “on the main branch”, you can conclude that D is part of a “patch branch”. It’s quite clear if you don’t omit this fact.I also don’t understand why your example would have multiple merges.
Here’s my example of a main branch with a patch branch; in 2D because merges can’t properly be represented in one dimension:
M - A - B - C - C' \ / D - E - FThe final code ought to look the same, but now if you’re debugging you can’t separate the feature patch from the main path code to see which part was at fault.
If you use a feature branch workflow and your main branch is merged into, you typically want to use first-parent bisects. They’re much faster too.




TS is a lot easier to set up than WG and does not require a publicly accessible IP address nor any public whatsoever. It’s not really comparable to setting WG up yourself; especially w.r.t. security.